RAG solves these problems by combining the reasoning capabilities of Large Language Models with external knowledge retrieval systems.
Instead of forcing the LLM to rely only on information stored inside its parameters, RAG allows the model to dynamically retrieve relevant information from external sources during inference.
This simple architectural shift fundamentally changes what AI systems can do.
Modern AI assistants, enterprise copilots, AI search engines, customer support bots, document intelligence systems, and coding assistants heavily depend on RAG architectures.
The Core Problem with Large Language Models (LLMs)
A standard LLM generates responses based entirely on patterns learned during training. For example, if you ask:What is Spring Boot?This works surprisingly well for general information. However, serious problems appear in real-world applications. LLMs suffer from several fundamental limitations:
1. They may generate incorrect information confidently.
2. They cannot access private company documents unless explicitly connected.
3. Their knowledge may become outdated after training.
4. They cannot reliably answer questions about dynamic data.
5. They struggle with enterprise-specific context.
For example:
What is our company's refund policy introduced last month?What Exactly Is RAG?
At a high level, RAG combines two systems: Retrieval System and Generative Model.The retrieval system fetches relevant information from external data sources. The generative model uses that retrieved information to generate grounded responses. Conceptually:
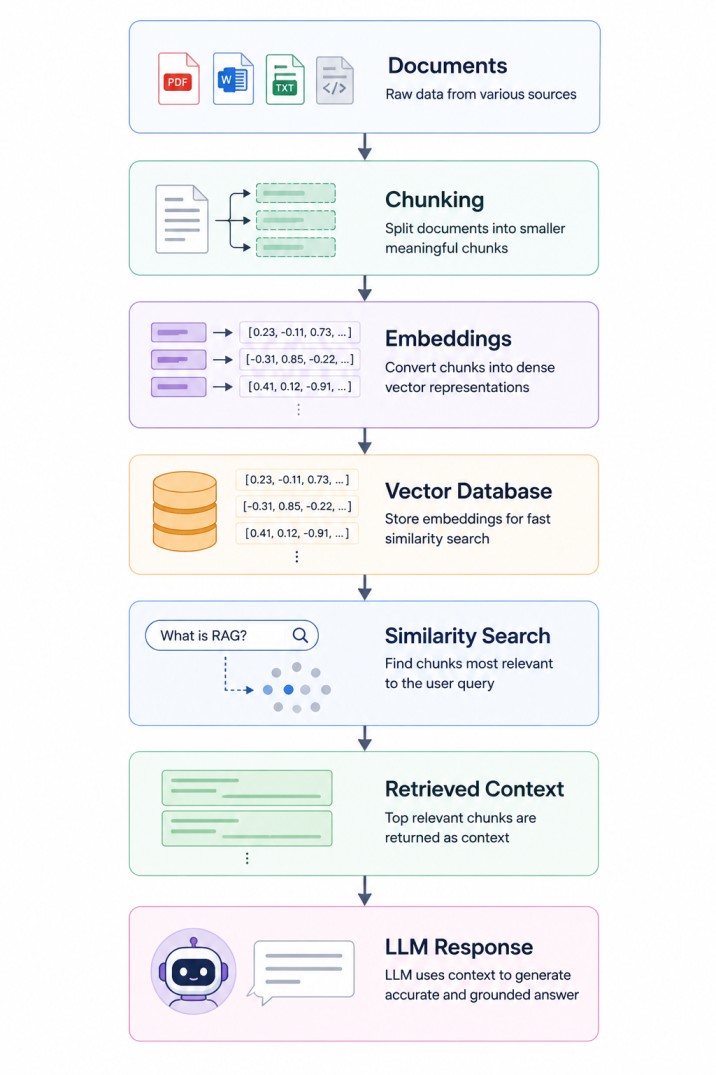
The Two Major Phases of RAG
A RAG pipeline typically consists of two major stages:1. Indexing Pipeline
2. Retrieval Pipeline
The indexing pipeline prepares documents for retrieval. The retrieval pipeline executes during user queries.
Understanding this separation is critical because indexing is usually performed offline, while retrieval happens in real time.
Phase 1: Document Ingestion
Everything begins with documents. These documents may come from many sources:1. PDFs.
2. Word documents.
3. Databases.
4. Confluence pages.
5. GitHub repositories.
6. Slack messages.
7. Websites.
8. Research papers.
9. Internal wikis.
10. Customer support tickets.
The ingestion layer collects and normalizes this information. For example:
PDF → Extract Text HTML → Remove Tags Markdown → Preserve Structure Code → Preserve SyntaxPhase 2: Chunking
Large documents cannot be embedded effectively as single units. Instead, documents are split into smaller segments called chunks.Chunking is one of the most important steps in RAG systems because retrieval quality depends heavily on chunk quality. Example:
Large Document ↓ Chunk 1 Chunk 2 Chunk 3 Chunk 41. Fixed-size chunking.
2. Recursive chunking.
3. Sentence-based chunking.
4. Semantic chunking.
5. Paragraph chunking.
6. Overlapping chunking.
A common implementation using
LangChain:
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
chunks = splitter.split_text(text)
Phase 3: Embedding Generation
Once chunks are created, they are converted into vector embeddings. Embeddings are dense numerical representations that capture semantic meaning. For example:"Spring Boot simplifies Java development"[0.23, -0.91, 0.44, ...]text-embedding-3-largeBGEE5InstructorMiniLM
Embedding generation pipeline:
Chunks ↓ Embedding Model ↓ Vector EmbeddingsPhase 4: Vector Database Storage
The generated embeddings are stored inside a Vector Database. Unlike traditional databases, vector databases are optimized for similarity search in high-dimensional space.Popular vector databases include:
1.
Pinecone2.
Weaviate3.
Milvus4.
Qdrant5.
FAISS6.
Chroma
Each stored entry typically contains:
1. The embedding vector.
2. Original chunk text.
3. Metadata.
4. Document identifiers.
5. Source references.
Example structure:
{
"id": "chunk-101",
"embedding": [0.12, -0.88, ...],
"text": "Spring Boot uses auto configuration...",
"metadata": {
"source": "spring-guide.pdf",
"page": 14
}
}
Phase 5: User Query Processing
When a user submits a question, the query itself is embedded using the same embedding model. For example:How does Spring Boot auto-configuration work?[0.17, -0.72, 0.41, ...]Phase 6: Similarity Search
Similarity search is the heart of retrieval. The vector database finds chunks whose embeddings are closest to the query embedding. Similarity is commonly measured using:1. Cosine Similarity
2. Dot Product
3. Euclidean Distance
Conceptually: CosineSimilarity(A, B) = (A · B) / (∥A∥∥B∥)
The top matching chunks are retrieved. Example:
Query: "How does Spring Boot auto-configuration work?"
Retrieved Chunks:
1. Auto-configuration overview
2. @Conditional annotations
3. Spring factories mechanism
Phase 7: Prompt Augmentation
The retrieved chunks are injected into the LLM prompt. This step is called Prompt Augmentation. Example:You are a helpful AI assistant. Context: [Retrieved Chunks] Question: How does Spring Boot auto-configuration work?
Phase 8: Response Generation
Finally, the LLM generates the answer using both:1. Its pretrained knowledge.
2. Retrieved contextual information.
This combination is what makes RAG so powerful. The model can now answer questions about:
1. Private enterprise data.
2. Recently updated documents.
3. Dynamic business information.
4. Internal codebases.
5. Custom knowledge repositories.
This effectively transforms a general-purpose LLM into a domain-specific intelligent assistant.
The Biggest Challenges in RAG Systems
Despite its power, building production-grade Retrieval-Augmented Generation (RAG) systems is far more challenging than simply connecting a language model to a vector database. Real-world RAG pipelines face numerous practical problems that directly affect answer quality, reliability, and scalability.1. Poor chunking strategies can split important context incorrectly, while weak embedding models may fail to capture the true semantic meaning of the content. Even when embeddings are good, systems often retrieve irrelevant documents, noisy passages, or duplicate chunks that reduce response quality.
2. Context window limitations create another challenge because only a limited amount of retrieved information can be injected into the model prompt at once.
3. Production systems must also deal with latency issues caused by embedding generation, vector search, reranking, and LLM inference.
4. More advanced reasoning tasks introduce additional complexity, especially when the answer requires multi-hop reasoning across multiple documents.
5. Ranking quality becomes critical because the model is only as good as the context it receives.
6. Security and access control are also major concerns in enterprise environments where sensitive documents must be filtered based on user permissions.
Many early RAG systems fail because teams underestimate the importance of retrieval quality and focus too heavily on prompt engineering alone.
Advanced RAG Architectures
Modern Retrieval-Augmented Generation (RAG) systems are evolving rapidly beyond basic vector similarity search. Advanced architectures now combine multiple retrieval and reasoning techniques to improve accuracy, contextual understanding, and response reliability.1. One important advancement is Hybrid Search, which combines semantic search with traditional keyword-based retrieval to capture both meaning and exact term matches.
2. Another major improvement comes from Re-ranking Models, where retrieved documents are further refined using cross-encoders that evaluate query-document relevance more precisely.
3. Parent-Child Retrieval addresses context fragmentation by retrieving smaller chunks for precision while expanding larger parent sections to preserve surrounding context.
4. More sophisticated systems are now adopting Graph RAG, which integrates knowledge graphs to enable relationship-aware retrieval across connected entities and concepts.
5. The rise of Agentic RAG introduces autonomous AI agents capable of performing iterative retrieval, reasoning, planning, and refinement steps before generating a final answer.
6. Another emerging approach is Multi-Vector Retrieval, where documents are represented using multiple embeddings to better capture different semantic perspectives within the same content.
7. In practice, modern enterprise AI systems increasingly combine several retrieval strategies together, creating more intelligent, scalable, and context-aware RAG pipelines capable of handling complex real-world tasks.
Building Real-World RAG Applications
Conclusion
Retrieval-Augmented Generation (RAG) is rapidly evolving into a foundational AI infrastructure layer for next-generation intelligent systems. Future AI architectures will increasingly integrate powerful capabilities such as long-context models, which can process significantly larger amounts of information, and advanced memory architectures that allow systems to retain and reuse knowledge across interactions.The integration of graph reasoning will enable AI systems to understand relationships between entities, concepts, and events more effectively, while multimodal retrieval will allow retrieval across text, images, audio, video, and structured data sources simultaneously.
The rise of agentic workflows will further transform RAG systems by enabling autonomous agents to perform iterative reasoning, planning, retrieval, and decision-making tasks dynamically.
Modern systems are also increasingly adopting tool augmentation, where AI models interact with external APIs, databases, calculators, search engines, and enterprise software systems to extend their capabilities beyond static language generation.
Alongside this, dynamic planning systems will help AI orchestrate complex multi-step workflows with adaptive reasoning and contextual awareness.
As AI systems become more deeply integrated into enterprise workflows, retrieval quality will emerge as one of the most important competitive advantages.
The future of enterprise AI is not simply about building larger language models with more parameters. Instead, it is about creating intelligent systems capable of retrieving, reasoning, verifying, and synthesizing information dynamically from massive external knowledge sources in real time. That is precisely what RAG enables.
In many ways, RAG represents the transition from standalone language models toward truly knowledge-connected AI systems that can interact with continuously evolving information ecosystems rather than relying solely on static training data.
If you want to see how these concepts come together in an actual application, you can explore this practical implementation: Building Intelligent Chatbots with LLM & RAG.
