Yet despite all these advances, computers traditionally struggled with something humans do effortlessly: understanding meaning.
Lexical matching (or lexical search) is a retrieval method that matches exact words or phrases between a query and a document. It relies on literal form and does not inherently understand context, meaning, or synonyms.
Semantic search is an advanced data-retrieval method that focuses on understanding the contextual meaning and intent behind a user's query. Instead of relying on exact keyword matches, it uses Natural Language Processing (NLP) and machine learning to interpret natural language and deliver highly relevant results.The breakthrough that enabled modern semantic search, recommendation systems, Retrieval-Augmented Generation (RAG), and large language models is the concept of embeddings. Embeddings transform language, images, code, and other forms of data into mathematical representations that capture meaning rather than mere textual appearance.
From Words to Numbers
Computers cannot directly understand text. Every machine learning model operates on numbers. Therefore, before a model can reason about language, the language must be converted into a numerical representation.The most naive approach is assigning an integer to each word. Suppose we create the following mapping:
cat → 1
dog → 2
car → 3
airplane → 4
cat and dog is numerically identical to the distance between dog and car, even though cats and dogs are semantically much closer.
Machine learning systems require a representation where similar concepts naturally appear close together. This requirement led to the development of vector representations.
Instead of representing a word as a single number, we represent it as a list of numbers. For example:
cat = [0.92, 0.11, 0.34, 0.67]
dog = [0.89, 0.14, 0.29, 0.71]
airplane = [0.03, 0.87, 0.95, 0.12]
This multidimensional space is known as an embedding space.
A vector in a vector database is a long list of numbers representing the meaning or characteristics of unstructured data (like text, images, or audio). Created by machine learning models, these numbers capture the context of the data so that items with similar meanings are mathematically grouped close together.
An embedding is a specific type of vector that acts as a mathematical translation of human concepts into a format that computers can understand.
While the terms are often used interchangeably, there is a technical distinction:
Vector: This is the generic mathematical format—simply an ordered list of numbers (like [0.23, -0.45, 0.89]).
Embedding: This is the meaningful result generated by an AI model.
An embedding is always a vector, but it is specifically a vector that successfully captures the semantic traits of the original data.
The Central Idea Behind Embeddings
The key insight behind embeddings is surprisingly simple. Words that appear in similar contexts tend to have similar meanings. This idea became famous through the linguistic principle often summarized as:"You shall know a word by the company it keeps."
Consider the following sentences:
The cat drank milk.
The dog drank milk.
The puppy drank milk.
Over millions or billions of training examples, the model gradually adjusts numerical representations so that these words become mathematically close together.
Meanwhile, words such as:
database
microservice
kubernetes
An embedding space is the multi-dimensional mathematical landscape where embeddings (the numerical representations of data) are placed. Unlike our physical world which has three dimensions (length, width, height), an embedding space usually has hundreds or thousands of dimensions.
Each dimension represents a subtle, hidden feature or concept learned by an AI model. Similarity is measured by physical distance. Items that share a similar meaning or context are clustered closely together, while unrelated items are pushed far apart.
Imagine a simplified, 3-dimensional embedding space mapping animals:
Dimension 1 (X-axis): Size (Small to Large)
Dimension 2 (Y-axis): Domesticity (Wild to Pet)
Dimension 3 (Z-axis): Environment (Land to Water)
In this space, a "Golden Retriever" and a "Poodle" would have almost identical coordinates, sitting right next to each other. A "Wolf" would be close in size and land environment, but far away on the domesticity axis. A "Blue Whale" would be pushed to the absolute extremes of size and water environment, far away from all of them.
How Embeddings Are Learned
Modern embeddings are not manually designed. They are learned during training. Imagine a neural network tasked with predicting missing words. Consider the sentence:The Eiffel Tower is located in _____
In the context of vectors and embedding spaces, parameters are the rules that determine exactly where a piece of data gets placed on that multi-dimensional map.
When an AI model is first built, its parameters are randomized. If you feed it the words "apple" and "banana," it might place them on opposite sides of the mathematical space because its parameters don't know any better These are updated automatically by the AI during training.
Examples include weights (how important a specific feature is) and biases (the baseline assumptions the model makes). When you hear that an LLM has "70 billion parameters," it means the model has 70 billion individual mathematical dials it uses to process information.
When an LLM has 70 billion parameters, it means the model contains 70 billion individual numbers (weights and biases) stored in its memory.The model generates an incorrect prediction, computes the error, and performs backpropagation. During this optimization process, millions or billions of parameters are adjusted.
Here is exactly what that means:
1. Each parameter is a mathematical value that dictates how input data gets transformed.
2. When you type a prompt, your words pass through a massive web of 70 billion mathematical equations.
3. These numbers determine how much attention words pay to each other, allowing the model to calculate and predict the next most logical word in a sentence.
In short, more parameters mean a larger mathematical map, allowing the model to recognize more complex patterns, facts, and nuances.
One subset of these parameters corresponds to the embedding vectors. Over many training iterations, words that contribute to similar predictions gradually move closer together within the embedding space.
This process occurs across enormous corpora consisting of books, articles, websites, source code repositories, support tickets, emails, and many other data sources.
Eventually the learned vectors begin encoding rich semantic information.
Interestingly, nobody explicitly teaches the model concepts such as countries, professions, programming languages, or emotions. These structures emerge naturally because they are useful for prediction.
Word2Vec is a groundbreaking Natural Language Processing (NLP) technique developed by Google that converts words into numerical vectors.
The Evolution from Word Embeddings to Contextual Embeddings
Early embedding systems such as Word2Vec represented each word using a single fixed vector. For example:bank = [0.21, 0.83, 0.11, ...]
What the Numbers Represent?This created an important limitation. The word "bank" can mean:
Each number represents a hidden concept or "feature" (like royalty, femininity, speed, or liquidity). A high positive number means a strong connection to that concept. A negative number means the opposite.
Imagine an AI uses only three dimensions to understand words: [Is it alive?, Is it royal?, Is it female?].
The words would get numbers (vectors) like this:
King = [0.99, 0.95, 0.05] (Highly alive, highly royal, very low female)
Queen = [0.99, 0.96, 0.93] (Highly alive, highly royal, highly female)
Apple = [0.10, 0.01, 0.02] (Low on life, not royal, not female)
In real systems like Word2Vec, there are usually 100 to 300+ numbers per word. Humans cannot easily label what each specific dimension means, but the computer uses them to calculate similarities
river bank
financial bank
Consider the following sentences:
I deposited money in the bank.
The fisherman sat on the river bank.
As a result, the model understands that the two usages represent entirely different concepts. This contextual understanding is one of the primary reasons modern embedding models outperform older approaches.
The Transformer architecture solved a massive problem in AI: it allowed models to process entire sentences all at once, rather than word by word.
Before Transformers, AI utilized Recurrent Neural Networks (RNNs). RNNs read text like a human does: left to right, one word at a time. This caused two major issues: forgetfulness and slowness.
Transformers, however, process all words simultaneously using a mechanism called self-attention to determine how every word in a sentence relates to every other word.
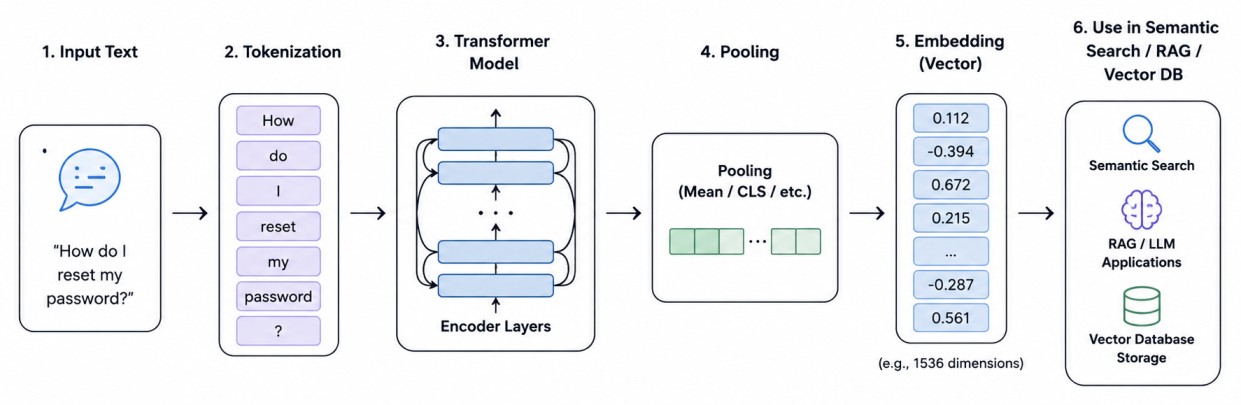
How Transformers Produce Embeddings
Most modern embedding models are built upon the transformer architecture. The process begins with tokenization.The sentence:
How do I reset my password?
["How", "do", "I", "reset", "my", "password", "?"]
Self-attention allows each token to examine every other token in a sentence to determine which words are most important. For example, when processing the token "password," the model may assign significant attention to "reset," "my," "password," and "?" while largely ignoring less informative words like "How," "do," and "I."
As information flows through many transformer layers, each token accumulates contextual knowledge about the entire sentence. By the final layer, the representation of "password" no longer reflects just the word itself. It reflects its role within the entire sentence.
The resulting vectors are extraordinarily rich semantic representations.
Creating a Sentence Embedding
A transformer naturally produces embeddings for individual tokens. Semantic search, however, usually requires a single embedding representing an entire sentence or document.Several pooling strategies exist. The simplest approach computes the average of all token vectors.
sentence_embedding =
average(token1, token2, token3, ...)
[CLS]. CLS is a special token introduced by Google's BERT model. It acts as a master "summary token" for an entire sentence or paragraph.
Some employ sophisticated pooling mechanisms optimized specifically for retrieval tasks. The final result is typically a dense vector containing hundreds or thousands of dimensions. For example:
[0.112, -0.394, 0.672, ..., 0.287]
Why Similar Meanings End Up Close Together
Suppose we embed the following sentences:How do I reset my password?
I forgot my login credentials.
Meanwhile:
Deploy a Kubernetes cluster.
In high-dimensional space, semantic similarity becomes geometric proximity. This simple idea powers virtually every modern retrieval system. Instead of searching for matching words, systems search for nearby vectors.
The retrieval problem becomes a mathematical nearest-neighbor problem.
Dimensions and Their Meaning
Suppose an embedding has 1536 dimensions.Does dimension 217 represent sentiment?
Does dimension 892 represent geography?
Generally, no.
Unlike traditional features engineered by humans, embedding dimensions are distributed representations. Meaning is encoded collectively across many dimensions.
No single dimension typically corresponds to a human-interpretable concept. Instead, the overall pattern across the entire vector captures semantic information.
This distributed representation is one reason embeddings are so powerful.
Example: Customer Support Search
Consider a company with ten million support tickets accumulated over several years. A traditional search engine may fail when a customer searches:Unable to sign in after password update
Login failure following credential change
Embedding-based retrieval solves this elegantly.
1. Every ticket is converted into an embedding and stored.
2. When a query arrives, its embedding is generated. The system retrieves vectors nearest to the query vector.
3. Despite completely different wording, semantically similar tickets are returned.
Generating Embeddings with OpenAI
Generating embeddings is remarkably simple. The complexity resides within the model itself.Python example
from openai import OpenAI
client = OpenAI()
response = client.embeddings.create(
model="text-embedding-3-large",
input="How do I reset my password?"
)
embedding = response.data[0].embedding
print(len(embedding))
Java example
@Autowired
private EmbeddingModel embeddingModel;
public List createEmbedding(String text) {
EmbeddingResponse response =
embeddingModel.call(
new EmbeddingRequest(
List.of(text)
)
);
return response.getResults()
.get(0)
.getOutput();
}
Conclusion
Embeddings represent one of the most important ideas in modern artificial intelligence. They convert language, code, images, and other unstructured information into mathematical representations that preserve meaning.Through large-scale training and transformer architectures, semantically related concepts naturally become neighbors in a high-dimensional space. This transformation allows machines to move beyond keyword matching and perform genuine semantic retrieval.
Every production-grade RAG system, recommendation engine, semantic search platform, AI assistant, and vector database relies on them.
In the next article, we will build upon this foundation and explore how vector databases store billions of embeddings, perform similarity search in milliseconds, and power retrieval systems at internet scale.
