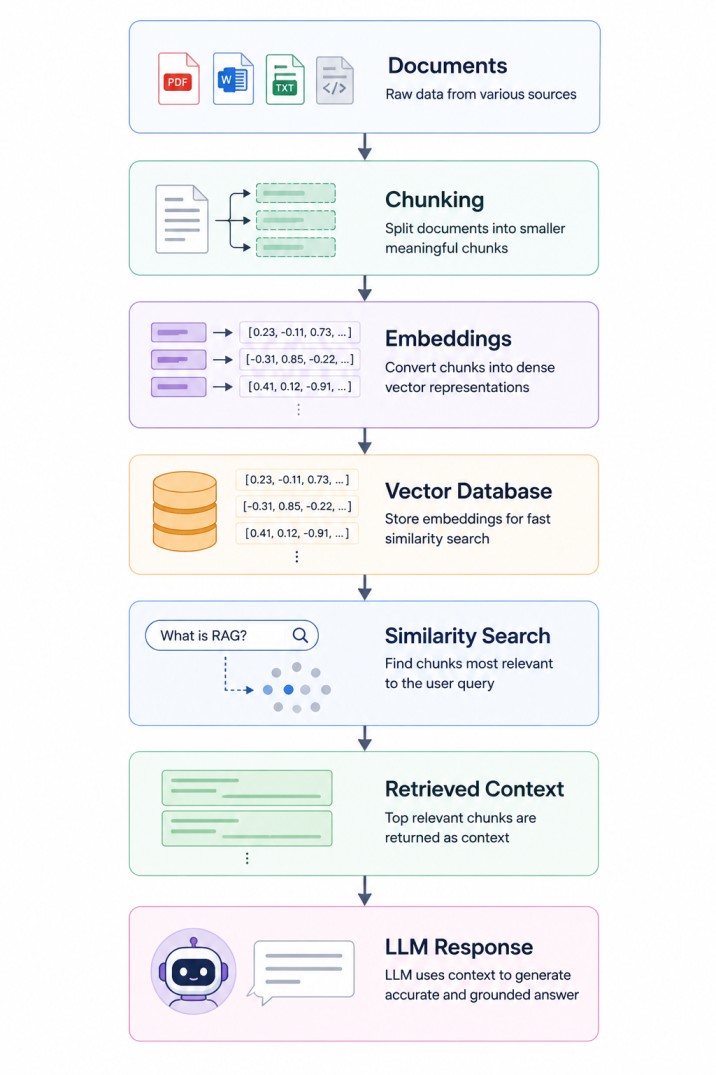
Instead of storing an entire book, PDF, research paper, or long article as a single embedding, the content is divided into smaller semantic units called chunks. These chunks become the fundamental retrieval units of the RAG pipeline.
The primary goal of chunking is to improve retrieval precision. Embedding models convert text into high-dimensional vectors that capture semantic meaning. However, when an entire large document is represented by a single embedding, the resulting vector becomes overly broad and diluted. Important details are merged into a generalized representation, making it difficult for similarity search to identify the exact section relevant to a user query.
For example, consider a 200-page software architecture document containing sections on authentication, caching, Kubernetes deployment, monitoring, and distributed systems. If the entire document is stored as a single embedding, a query such as:
“How is JWT refresh token rotation implemented?”
may fail to retrieve the correct information because the embedding represents the document’s overall theme rather than the specific authentication section.
Chunking solves this problem by breaking the document into smaller, semantically meaningful pieces. Each chunk receives its own embedding, allowing the retrieval system to identify highly relevant sections with much greater accuracy. As a result, a query about JWT refresh tokens can directly retrieve the authentication-related chunk instead of the entire document.
These chunk embeddings are stored inside a vector database such as Pinecone, Weaviate, Milvus, Qdrant, or FAISS.
When a user submits a query, the system generates an embedding for the query and performs a similarity search against the stored chunk embeddings. The most relevant chunks are then retrieved and supplied to the LLM as contextual knowledge.
Well-designed chunking, on the other hand, improves retrieval accuracy, reduces hallucinations, optimizes context utilization, and enables the model to generate responses that are more precise, relevant, and context-aware.
1) Why is chunking important in RAG systems?
Chunking is important because it improves retrieval precision. Instead of embedding an entire large document as one vector, the document is divided into smaller semantic units called chunks. This allows the retrieval system to fetch only the most relevant sections for a user query. Good chunking improves retrieval accuracy, reduces hallucinations, and provides better context to the LLM.
The Core Tradeoff in Chunking
Every chunking strategy revolves around balancing two competing goals: Context Preservation and Retrieval Precision.Larger chunks preserve more context but reduce retrieval specificity. Smaller chunks improve precision but may lose important surrounding information.
Suppose a legal document contains this sentence:
The agreement may be terminated if payment is not received within 45 days."...terminated if payment..."On the other hand, if the chunk contains 20 unrelated paragraphs, semantic similarity becomes diluted and retrieval accuracy decreases.
This balancing act is the central challenge of chunking design.
Fixed-Size Chunking
The simplest approach is Fixed-Size Chunking. Documents are split after a fixed number of characters, words, or tokens. Example:chunk_size = 500chunk_size = 1024 tokensA basic implementation may look like:
def chunk_text(text, chunk_size):
chunks = []
for i in range(0, len(text), chunk_size):
chunks.append(text[i:i + chunk_size])
return chunks
2. Paragraphs may split in the middle.
3. Code blocks may break incorrectly.
4. Tables and structured content may become corrupted.
5. Sentence continuity may be destroyed.
Still, fixed-size chunking remains surprisingly effective for many large-scale pipelines because of its simplicity and predictability.
Overlapping Chunking
One of the most common improvements is Chunk Overlap. Instead of splitting chunks independently, neighboring chunks share overlapping content. Example:Chunk 1: Tokens 1–500
Chunk 2: Tokens 450–950
A simple implementation:
def chunk_with_overlap(text, chunk_size, overlap):
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunks.append(text[start:end])
start += chunk_size - overlap
return chunks
However, excessive overlap introduces duplication. This increases:
1. Embedding costs.
2. Storage usage.
3. Retrieval redundancy.
4. Inference token consumption.
Most production systems use overlaps between 10% and 30% of chunk size.
Sentence-Based Chunking
A more intelligent approach is Sentence-Based Chunking. Instead of arbitrary token boundaries, documents are split using sentence boundaries. For example:import nltk
sentences = nltk.sent_tokenize(text)
Sentence chunking is particularly effective for:
1. Technical documentation.
2. Research papers.
3. Knowledge bases.
4. Educational content.
5. News articles.
However, sentence chunking alone is not always sufficient because related ideas may span multiple paragraphs.
Semantic relationships in long-form documents often extend beyond sentence boundaries.
Paragraph-Based Chunking
Paragraph-based chunking respects natural document structure. Each paragraph or group of paragraphs becomes a chunk.This approach works especially well for:
1. Blogs.
2. Books.
3. Legal documents.
4. Technical articles.
5. Markdown documentation.
6. Educational material.
Paragraph chunking preserves topic coherence much better than fixed token splitting.
For example, a paragraph explaining
Transformer Attention remains intact rather than fragmented across chunks.
The downside is inconsistency in chunk size. Some paragraphs may be extremely short while others become excessively large. This creates uneven embedding density and retrieval behavior.
Semantic Chunking
One of the most advanced approaches is Semantic Chunking. Instead of relying purely on length or formatting boundaries, semantic chunking attempts to split documents according to meaning.The system analyzes semantic similarity between neighboring sentences and detects topic shifts. Conceptually:
Topic A Topic A Topic A
---- semantic boundary ----
Topic B Topic B
A semantic chunker may:
1. Compute embeddings for sentences.
2. Measure cosine similarity between adjacent sentences.
3. Create new chunks when similarity drops below a threshold.
Pseudo-flow:
Sentence Embeddings → Similarity Comparison → Boundary Detection → Semantic Chunks1. Enterprise knowledge bases.
2. Research documents.
3. Multi-topic reports.
4. Large technical manuals.
5. Long conversational transcripts.
The tradeoff is computational cost. Semantic chunking is significantly slower and more complex than fixed splitting.
Recursive Chunking
Modern frameworks such as LangChain popularized Recursive Chunking. This approach attempts splitting hierarchically using progressively smaller separators. For example:separators = [ "\n\n", "\n", ".", " ", "" ]This preserves structure whenever possible while guaranteeing size constraints.
Example using LangChain:
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
chunks = splitter.split_text(text)
Document-Aware Chunking
One of the biggest mistakes in RAG systems is treating all documents identically. Different content types require different chunking strategies. For example:- Codebases should chunk around functions, classes, or modules.
- Markdown documents should chunk around headings.
- HTML pages should preserve DOM structure.
- PDFs should preserve sections and tables.
- Legal contracts should preserve clauses.
- Research papers should preserve sections like abstract, methodology, and conclusions.
This approach is called Document-Aware Chunking. Instead of generic splitting, the system understands document structure before chunking.
This often produces major improvements in enterprise retrieval quality.
Chunking for Code RAG Systems
Chunking source code introduces unique challenges. Naively splitting code by token count is usually disastrous.Breaking a function midway destroys semantic meaning. For code retrieval systems, chunk boundaries should align with logical program structure.
Good chunk units include:
1. Functions.
2. Classes.
3. Interfaces.
4. Modules.
5. Configuration blocks.
6. API routes.
Example:
public class PaymentService {
public PaymentResponse processPayment() {
...
}
}2) How do you choose chunk size for documents?
Chunk size is chosen based on the tradeoff between retrieval precision and context preservation.
- Smaller chunks improve retrieval precision but may lose surrounding context.
- Larger chunks preserve context but may introduce irrelevant information.
Typical production setups use:The ideal chunk size depends on document type, embedding model, query patterns, and LLM context window.Chunk Size: 300–800 tokens Overlap: 50–150 tokens
The Relationship Between Chunk Size and Embeddings
Chunking directly affects embedding quality. Embedding models compress semantic meaning into fixed-length vectors.When chunks become excessively large, embeddings represent multiple unrelated concepts simultaneously. This semantic dilution weakens similarity search.
Conversely, extremely tiny chunks may lack sufficient semantic information. For example:
"However the system failed."1. Embedding model.
2. Document type.
3. Query patterns.
4. Retrieval architecture.
5. LLM context window.
Production systems often empirically tune chunk sizes through retrieval evaluation rather than theoretical assumptions.
Hierarchical Retrieval and Parent-Child Chunking
Advanced RAG systems often use Hierarchical Retrieval. Instead of storing only one chunk granularity, systems maintain both small and large chunks. For example:Child chunks enable precise retrieval.
Parent chunks provide broader context.
Flow:
Retrieve Small Chunk → Locate Parent Section → Expand Context → Send to LLM3) Difference between Sparse and Dense Retrieval?Modern RAG systems often use Hybrid Retrieval, combining both approaches.
Feature Sparse Retrieval Dense Retrieval Technique Keyword matching Embedding similarity Understanding Lexical matching Semantic matching Examples BM25, TF-IDF Vector Search Strength Exact keyword search Semantic understanding Weakness Poor semantic matching May miss exact terms
Evaluating Chunking Quality
Chunking quality should never be judged subjectively. Production RAG systems require measurable evaluation. Important evaluation metrics include:1. Retrieval Precision
2. Recall
3. MRR (Mean Reciprocal Rank)
4. Context Relevance
5. Answer Faithfulness
6. Latency
7. Token Usage
A chunking strategy that appears theoretically elegant may fail under real-world query distributions. The best chunking strategy is usually discovered through iterative experimentation and retrieval benchmarking.
4) What causes poor retrieval quality in RAG pipelines?
Common causes include:
1. Poor chunking strategy
2. Chunks that are too large or too small
3. Missing chunk overlap
4. Weak embedding models
5. Bad document preprocessing
6. OCR errors in PDFs
7. Poor metadata filtering
8. Weak semantic search
9. Missing reranking stage
10. Lack of hybrid retrieval
Poor retrieval usually happens when retrieved chunks are irrelevant, fragmented, or semantically diluted.
The Future of Chunking
Chunking strategies are evolving rapidly as context windows become larger and retrieval architectures become more sophisticated. Modern systems increasingly combine:1. Semantic chunking.
2. Graph retrieval.
3. Knowledge-aware segmentation.
4. Agentic retrieval pipelines.
5. Dynamic context assembly.
Future RAG systems may move beyond static chunking entirely toward adaptive retrieval systems that construct contextual units dynamically at query time.
Even so, chunking remains foundational today. In many production AI systems, retrieval quality improves more from better chunking than from upgrading to a larger language model.
The effectiveness of a RAG system is often determined long before the prompt ever reaches the LLM.
