The Meaning of GPT
The term GPT stands for Generative Pre-trained Transformer.The word Generative means the model can generate new content rather than simply classify existing data. The word Pre-trained refers to the fact that the model is first trained on enormous datasets before being adapted for real-world use cases.
The word Transformer refers to the "deep learning" architecture introduced in the landmark paper "Attention Is All You Need", which revolutionized natural language processing.
Before transformers, Natural Language Processing (NLP) systems relied heavily on Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM).
These older architectures processed words sequentially, making them slow and poor at capturing very long dependencies. Transformers changed the game by introducing self-attention, allowing models to understand relationships between words regardless of their distance in a sentence.
That innovation became the backbone of modern AI systems including GPT, Claude, Gemini, and many other large language models.
Neural Networks (NNs)
Neural Networks are machine learning models inspired by the human brain, consisting of interconnected neurons organized into input, hidden, and output layers. They learn by adjusting weights during training to recognize patterns and make predictions.
They are widely used for classification, regression, computer vision, natural language processing (NLP), and speech recognition.
Recurrent Neural Networks (RNNs)
RNNs are neural networks designed for sequential data such as text, speech, and time-series. They maintain a hidden state (memory) that carries information from previous time steps, allowing the model to learn temporal dependencies.
Long Short-Term Memory (LSTM)
LSTM is an advanced type of RNN that solves the vanishing gradient problem using input, forget, and output gates. It can capture long-term dependencies, making it effective for language modeling, translation, and speech recognition.
Transformer
Transformers replace recurrence with the Self-Attention mechanism, enabling all words in a sequence to be processed in parallel. They train much faster than RNNs/LSTMs, capture long-range relationships effectively, and power modern Large Language Models (LLMs) like GPT, BERT, and Gemini.
Tokens
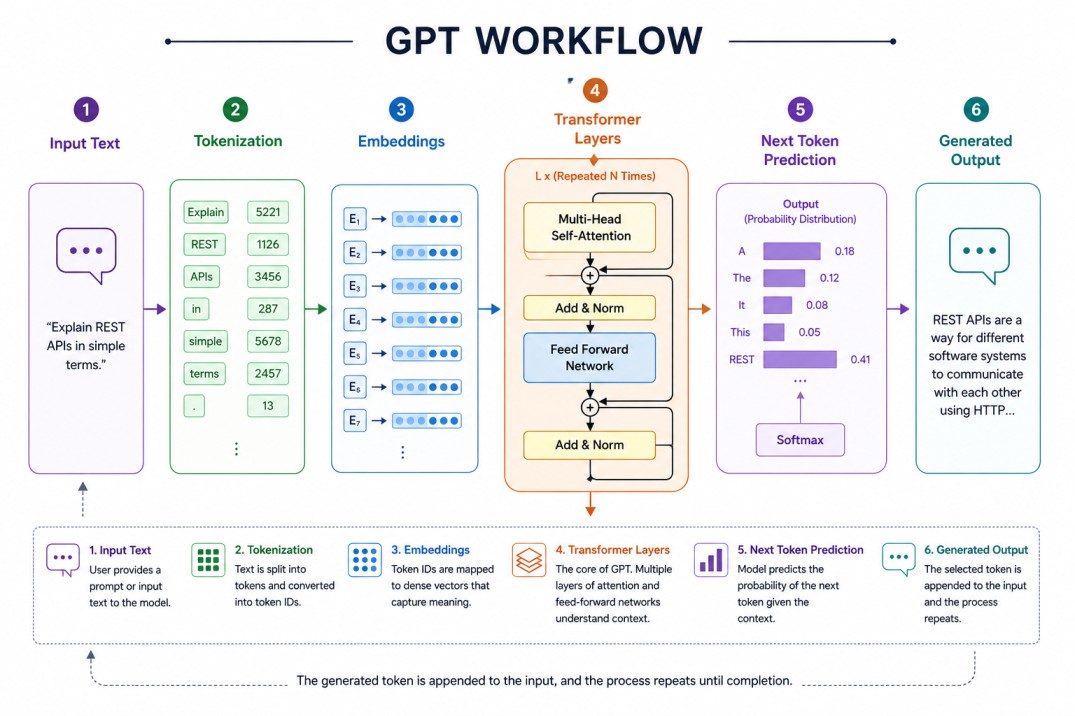
Humans think in words and sentences, but neural networks work with numbers. Before a GPT model can understand language, text must be converted into smaller units called tokens.A token may represent an entire word, part of a word, punctuation, or even whitespace. For example, the sentence:
Machine learning is powerful.["Machine", " learning", " is", " powerful", "."][4152, 7821, 318, 9912, 13]Words with similar meanings often end up having embedding vectors close to each other in high-dimensional space. For example, embeddings for “king” and “queen” will likely share many properties. Similarly, “Java” and “Spring Boot” may cluster in related regions for software-oriented models.
The Transformer Architecture
At the heart of GPT lies the Transformer architecture.The Transformer processes input tokens in parallel instead of sequentially. This massively improves training efficiency and enables the model to scale to billions or even trillions of parameters.
A GPT model contains multiple stacked layers of neural network components. Each layer progressively refines the understanding of the text.
The most important mechanism inside the Transformer is Self-Attention.
![]()
Understanding Self-Attention
Self-attention is the core reason GPT models are so effective.When humans read a sentence, we naturally connect words together based on context. In the sentence:
The server crashed because it ran out of memory.A GPT model performs a mathematically similar operation using attention mechanisms.
For every token, the model calculates how strongly it should “pay attention” to every other token in the sequence. This enables contextual understanding.

The attention score is calculated by comparing queries and keys. Conceptually: attention_score = Query × Key
The scores are normalized using Softmax, producing probabilities that determine how much influence each token should have.
The famous attention formula looks like this: Attention(Q, K, V) = softmax((QKT) / √dk) V
This operation happens across multiple layers and multiple attention heads simultaneously. The result is that GPT develops an internal representation of grammar, meaning, relationships, logic patterns, and contextual dependencies.
Why Multi-Head Attention Matters
A single attention mechanism is limited. Different relationships in language require different perspectives.One attention head may focus on grammatical structure, another on semantic meaning, another on long-range dependencies, and another on code syntax. This is why Transformers use Multi-Head Attention.
Instead of computing one attention operation, the model computes many in parallel. This allows GPT to capture multiple contextual relationships simultaneously, which significantly improves language understanding.
Positional Encoding and Word Order
Transformers process tokens in parallel, but language depends heavily on order. The sentences:Dog bites man.Man bites dog.To preserve order information, GPT models use Positional Encoding. These encodings inject information about token positions into embeddings so the model understands sequence structure.
Without positional information, the Transformer would treat language like an unordered bag of words.
The Training Process
GPT models are trained on enormous amounts of text collected from books, articles, websites, code repositories, research papers, and many other sources.The training objective is deceptively simple: Predict the next token.
For example:
Input: "Java is a programming" Target: "language"Input: "Spring Boot simplifies" Target: "development"The model adjusts its internal weights using Backpropagation and Gradient Descent.
The optimization objective is minimizing Loss, usually Cross-Entropy Loss for language modeling tasks.
Conceptually: L = - ∑ y log(ŷ)
Over time, the model becomes increasingly accurate at predicting plausible continuations.
What appears as “intelligence” is fundamentally the result of learning highly sophisticated statistical representations from massive datasets.
Parameters and Scale
One of the defining characteristics of GPT systems is their enormous scale.A parameter is essentially a learned weight inside the neural network. During training, these weights are adjusted to encode patterns in data.
Smaller models may contain millions of parameters. Modern large language models contain billions or even trillions.
More parameters generally allow the model to capture more complex relationships, though scaling also introduces engineering challenges involving memory, compute, latency, optimization stability, and inference cost.
Training large GPT models requires distributed GPU clusters, high-bandwidth networking, mixed-precision computation, and highly optimized parallelism strategies.
Inference: How GPT Generates Responses
Once training is complete, the model enters the inference phase.Suppose a user enters the prompt:
Explain REST APIs in simple terms.For example:
["A" → 0.18 "REST" → 0.41 "The" → 0.09]Common decoding methods include:
- Greedy Decoding, where the highest-probability token is always selected.
- Temperature Sampling, which controls randomness.
- Top-k Sampling, which restricts selection to the top K candidates.
- Top-p Sampling, also called nucleus sampling, which dynamically chooses from the smallest probability set whose cumulative probability exceeds a threshold.
This process repeats token by token until the response is complete.
Importantly, GPT does not generate an entire paragraph at once. It generates one token at a time in an autoregressive loop.
Why GPT Sometimes Hallucinates
One common misconception is that GPT models “know” facts like humans do.In reality, GPT models are prediction engines trained on statistical patterns. They do not possess grounded understanding, consciousness, or true reasoning in the human sense.
This explains hallucinations — situations where the model produces plausible but incorrect information.
If the training data contains ambiguity, conflicting patterns, or insufficient context, the model may confidently generate inaccurate responses because its objective is probability optimization, not truth verification.
Modern AI systems mitigate this using techniques such as: Reinforcement Learning from Human Feedback (RLHF), retrieval augmentation, tool usage, safety tuning, and external memory systems.
These improvements significantly increase reliability but do not eliminate hallucinations completely.
Fine-Tuning and Instruction Tuning
Base GPT models are typically trained using generic internet-scale datasets. However, raw pretraining alone does not produce highly useful assistants.To make models more aligned with human expectations, developers apply Fine-Tuning. Fine-tuning trains the model further on specialized datasets. For example, a healthcare AI system might be fine-tuned on medical literature, while a coding assistant may be trained heavily on repositories and documentation.
Another important technique is Instruction Tuning.< Here, the model learns how to follow prompts such as:
"Summarize this article.""Write a Python function."Context Windows and Memory Limitations
GPT models do not possess persistent memory in the human sense. Instead, they rely on a Context Window.The context window defines how many tokens the model can consider simultaneously. Everything outside the context window is effectively forgotten unless external memory systems are introduced.
Larger context windows enable handling long documents, multi-turn conversations, and large codebases more effectively, but they also increase computational cost because attention complexity grows rapidly with sequence length.
Why GPT Models Are So Computationally Expensive
Training a modern GPT model is one of the most computationally demanding tasks in software engineering.Massive GPU clusters run for weeks or months processing trillions of tokens.
The computational complexity of self-attention increases significantly with sequence length, making optimization crucial. Techniques such as Flash Attention, Quantization, Mixture of Experts (MoE), and Tensor Parallelism are used to improve efficiency.
Inference itself is also expensive because responses are generated sequentially token by token rather than fully parallelized.
This is why serving large AI systems at internet scale requires sophisticated infrastructure engineering.
Conclusion
GPT models represent a convergence of several decades of research in artificial intelligence, distributed systems, mathematics, optimization, and computational hardware.What makes these systems remarkable is not merely their ability to generate text, but their emergence of generalized pattern recognition across domains such as language, programming, mathematics, reasoning, summarization, and creative generation.
Yet beneath the apparent intelligence lies a surprisingly elegant core principle: predict the next token using learned statistical patterns from massive amounts of data.
Everything else — conversation, coding assistance, summarization, translation, explanation, and content generation — emerges from that foundation combined with scale, architecture design, and optimization.
The era when AI was considered a niche specialization is ending. Understanding GPT models today is becoming as fundamental for modern engineers as understanding databases, networking, or distributed systems.
