A strong answer begins by clarifying scope. URL shorteners can vary widely. Some systems only generate short links, while others include custom aliases, analytics, expiration, QR codes, spam detection, and enterprise dashboards.
Understanding Requirements
In a time-limited interview, define the scope first. Assume we are designing a system that supports:1. URL shortening (long → short)
2. Redirection (short → long)
3. Custom aliases
4. Expiration support
5. Click tracking (basic analytics)
This scope is sufficient to demonstrate strong system design thinking.
Functional Requirements
1. The system should allow users to submit a long URL and receive a short unique URL.2. When a user visits the short URL, the system should redirect them quickly to the original destination.
3. Users may optionally choose a custom alias instead of a randomly generated ID.
4. The platform should maintain a click count for each URL.
5. It should also support link expiration where applicable.
Non-Functional Requirements
1. The system must be highly scalable, handling millions of new URLs and billions of redirects.2. Redirection latency should be extremely low, ideally within milliseconds.
3. The platform must be highly available because broken links severely impact user trust.
4. Data must be reliable, ensuring no incorrect mappings occur.
5. Additionally, security is important to prevent misuse such as phishing or malicious redirects.
Estimating Scale
Suppose the system generates 100 million new URLs per month and handles 1 billion redirects per day.Writes per second:
100,000,000 / (30 × 86,400) ≈ 38 writes/secReads per second (redirects):
1,000,000,000 / 86,400 ≈ 11,574 reads/secThis clearly shows a read-heavy system. Peak traffic may be 3x to 5x higher:
Peak ≈ 50K+ redirects/secThis justifies heavy use of caching, CDN, and horizontally scalable services.
Request Flow
The system has two primary flows depending on the type of operation being performed: URL creation and URL redirection. These flows differ significantly in terms of latency requirements, processing logic, and system load.1. URL Creation (Write Path)
When a user submits a long URL, the system generates a short URL and stores the mapping.Client → API Gateway → URL Service → DBThe client sends an HTTPS request containing the long URL and optionally a custom alias to the API layer. The request is routed to the URL Service, which first validates the input URL and checks if a custom alias is provided.
If a custom alias is requested, the system checks whether it already exists in the database. If the alias is already taken, the request is rejected. If not, the alias is reserved and used as the short URL.
If no alias is provided, the system generates a unique ID, typically using an auto-increment counter or distributed ID generator, and encodes it using Base62 to produce a compact short code.
The system then stores the mapping:
short_code → long_url along with metadata such as created_at, expires_at, and initial click_count = 0.
Once the mapping is successfully persisted, the system returns the generated short URL to the client:
https://short.ly/abc1232. URL Redirection (Read Path)
When a user visits a short URL, the system must quickly resolve it and redirect the user to the original destination.Client → CDN/Cache → URL Service → DB → RedirectThe client sends a request to the short URL. The system first checks the CDN or cache layer to see if the mapping is already available.
If the mapping is found in cache, the system immediately retrieves the long URL and returns an HTTP redirect response:
HTTP 302 → Location: https://example.com/very/long/urlAt the same time, the system records a click event. Instead of updating the database synchronously on every request (which would increase latency), the system publishes an event to a queue for asynchronous processing.
Click Event → Queue → Analytics Service → DB (increment count)This design ensures that the read path remains extremely fast, while analytics and secondary operations are handled asynchronously.
High-Level Architecture
At a high level, the system consists of clients interacting with backend services through APIs, with strong emphasis on fast read performance.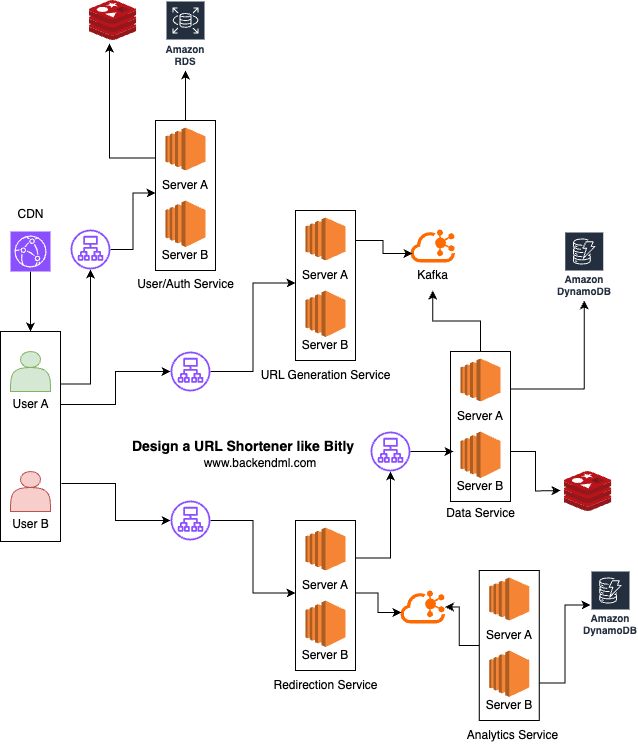
Major Components
Client
At a high level, the system is designed for two types of users:1) URL Creation: A registered user who registers a URL with the application and receives a short URL in return. For creation, the client sends an HTTPS request containing the long URL.
2) Redirection: Non-registered users who click on the short URL and are redirected to the actual URL. For redirection, the client simply visits the short URL, triggering a fast lookup and redirect.
CDN / Edge Layer
The CDN / Edge Layer serves static assets such as HTML, CSS, JavaScript, and images from edge locations closer to users, significantly reducing latency and offloading traffic from backend servers. It caches content across globally distributed edge nodes to ensure fast and reliable delivery.Example: AWS CloudFront delivers web app assets from Amazon S3 or origin servers with low latency and high availability worldwide.
User/Auth Service
The User Service is responsible for user identity and account lifecycle management, including registration, authentication, profile management, and session handling. All communication with this service happens over HTTPS, ensuring secure request-response interactions.During registration, the client creates an account using a phone number or email and verifies identity via OTP. The client first calls
/send-otp over HTTPS, where the OTP is temporarily stored in Redis with a TTL. It then calls /verify-otp, and upon successful verification, the user is created in the database.
For login, the client sends a request to
/login with credentials (OTP or password), which are validated before generating a JWT token. A session is also stored in Redis, and the token is returned to the client. A /logout request invalidates the session.
In addition, the User Service handles profile management, allowing users to fetch their details using
/me and update information such as name, photo, and preferences via /profile.
URL Generation Service
TheURL Service is responsible for generating short IDs, validating custom aliases, and producing mappings between short and long URLs to Kafka. It also ensures uniqueness and prevents collisions.
Generating short URLs is one of the most critical parts of the system because it directly affects uniqueness, scalability, performance, and security. Different strategies come with clear trade-offs, and understanding them with concrete examples strengthens the design.
1) Sequential ID Generation
One of the most common approaches is using a sequential ID with Base62 encoding. The system generates a unique numeric ID and encodes it.ID: 1000001 → Base62: 4c921) Security / Predictability: Sequential IDs are easy to guess because they follow a pattern.
short.ly/4c92
short.ly/4c93
short.ly/4c94
2) Centralized Bottleneck (Scalability Issue): If you use a single auto-increment counter, all writes depend on one source.
DB sequence → next_id()To address this, systems introduce ID range allocation and distributed ID generators, but that adds complexity.
ID range allocation
ID range allocation is a practical way to scale the sequential ID approach without relying on a single global counter. Instead of every request hitting a central database sequence, the system allocates blocks (ranges) of IDs to different application servers.Now, each server can generate IDs locally in memory without contacting the database for every request:DB allocates: Server A → IDs 1 to 1,000,000 Server B → IDs 1,000,001 to 2,000,000This removes the hotspot problem and significantly improves write throughput.Server A generates: 1, 2, 3, ... 999999
However, this approach introduces some trade-offs. If a server crashes before using its allocated range, a portion of IDs is wasted:Another consideration is range management. When a server exhausts its assigned range, it must request a new one from the database:Allocated: 1–1,000,000 Used: up to 200,000 Remaining IDs lostIf not handled carefully, this can still create periodic spikes in load on the allocation service.Request new range → DB → assign next block
Distributed ID generators
Distributed ID generators take scalability a step further by eliminating the need for a central allocator entirely. Each server generates globally unique IDs independently using a structured format.
A common approach is a Snowflake-like ID, which combines multiple components:The timestamp in the ID helps avoid collisions in case the sequence resets. Example breakdown:ID = timestamp + machine_id + sequence_numberThis ensures that IDs are:Timestamp → 41 bits Machine ID → 10 bits Sequence → 12 bits
- Globally unique
- Roughly time-ordered
- Generated without coordination
Example:This approach scales extremely well because every server can generate IDs independently, supporting high throughput and multi-region deployments.Generated ID: 728374982374 → Base62 → "fK92Lm"
However, it introduces its own trade-offs. The system must ensure that machine IDs are unique; otherwise, collisions can occur. It also depends on clock synchronization. The correctness of ID generation assumes that time never moves backward and remains reasonably consistent across machines.
Example issue:Even if we guarantee:Clock moves backward → duplicate or out-of-order IDs
1) Machine IDs are globally unique
2) The clock never moves backward
3) The sequence never resets incorrectly
There is no correctness trade-off (uniqueness is guaranteed). However, other trade-offs still exist.
Another trade-off is that IDs may be slightly longer than simple sequential IDs, although Base62 encoding keeps them compact.
Another limitation is related to throughput. In Snowflake-style ID generation, the sequence number is used to generate multiple unique IDs within the same millisecond. However, this sequence has a fixed number of bits, which directly limits how many IDs can be generated per unit time on a single machine.
For example, if the sequence is allocated 12 bits, then the maximum number of unique values it can represent is:A single machine can generate at most 4096 unique IDs per millisecond.2^12 = 4096
2) Hash-Based Generation
Another approach is hash-based generation, where the system hashes the long URL and truncates the result.hash("https://example.com/page1") → abcd1234 → abcd12Example collision scenario:
URL1 → hash → abcd12
URL2 → hash → abcd12 (collision)abcd12 → abcd12XWhy truncation introduces collisions?
When you hash a long URL using a strong hash (like MD5/SHA-256), the output is very large (e.g., 128-bit or 256-bit). This space is huge, so collisions are extremely unlikely.
Regardless of whether the input is a 10-character URL or a 1GB file, the algorithm always processes it into the same number of bits. Example (full hash):Now, to make URLs short, we truncate the hash:URL1 → hash → a94a8fe5ccb19ba61c4c0873d391e987982fbbd3 URL2 → hash → b6d767d2f8ed5d21a44b0e5886680cb9f2a8f7f1So:Take first 6 charsA full hash might have:URL1 → a94a8f URL2 → b6d767But a 6-character Base62 code has only:2^128 = 340 x 10^27 billion possible valuesThat seems large, but at scale (billions of URLs), the birthday paradox kicks in. Eventually, two different URLs will map to the same truncated value:62^6 ≈ 56 billion possibilitiesThis happens because you are compressing a huge space into a much smaller one. When a collision occurs, we need a way to generate a different output for the same input. We introduce a salt, a small extra value added before hashing:URL1 → hash → abcd12 URL2 → hash → abcd12 ← collisionhash(long_url + salt)Now the system retries until it finds a unique short code.hash(URL1 + "0") → abcd12 (collision) hash(URL1 + "1") → xk92Lm (new value)
Tradeoff:
- Extra computation
- Possible retries (latency)
Another approach is to increase the length of the short code when a collision occurs.Initial: 6 chars → abcd12 (collision) Extend to 7 chars → abcd123
Why this works: Longer code = larger address space and fewer chances of collision.Just adding one character massively reduces collision probability.62^6 ≈ 56 billion 62^7 ≈ 3.5 trillion
Rehashing with salt does not eliminate collisions; it reduces their probability. In rare cases where repeated collisions occur, the system retries with different salts and may dynamically increase the short code length or fall back to a deterministic ID generation strategy to guarantee uniqueness.
Even if you only have two URLs, they could theoretically collide. The number (2^256) represents the total number of "slots" available, not a capacity limit that prevents overlaps.
3) Random String Generation
A third approach is random string generation.generateRandom(6) → "aZ3kLm"Example:
Generated → aZ3kLm (already exists)Retry → bT9xQp4) Custom Aliases
Custom aliases introduce a different kind of trade-off. Suppose a user chooses:short.ly/sale- The alias is globally unique
- It is not reserved or abusive
- It does not conflict with system-generated IDs
Additionally, popular words may be taken quickly, leading to a poor user experience.
From a design perspective, the trade-offs can be summarized through real-world implications:
1) If you prioritize performance and simplicity, sequential IDs work best:
Fast writes, no collisions, but predictable URLs2) If you prioritize security and unpredictability, random or hash-based approaches are better:
Hard to guess, but require collision handling3) If you need massive scale in distributed systems, use distributed ID generators:
Globally unique, scalable, but more complexData Service
Once the URL Service generates a unique short code, instead of directly writing to databases, it publishes the mapping to a Kafka topic. This decouples the write path from storage, improves throughput, and increases resilience under spikes.Client → URL Service → Kafka → Data Service → (Redis + Cassandra){
"short_code": "abc123",
"long_url": "https://example.com/very/long/url",
"created_at": 1714550000,
"expires_at": 1717150000,
"user_id": "u123"
}- Persist to Cassandra (source of truth)
- Populate Redis (cache layer)
Multiple consumer instances can run in a consumer group.
The Cassandra schema is designed for O(1) lookup using the short code as the partition key.
INSERT INTO url_mapping (short_code, long_url, created_at, expires_at, user_id, is_active)
VALUES (
'abc123',
'https://example.com/very/long/url',
'2024-05-01 07:53:20',
'2024-05-31 10:06:40',
'u123',
TRUE
);
Key: short_code Value: long_url
SETEX url:abc123 86400 "https://example.com"We introduce a Data Service layer to centralize data access and simplify service boundaries. While this adds an extra network hop, we accept this tradeoff for better maintainability and consistency.
At very large scale, we can optimize further by allowing the Redirection Service to directly access Redis for hot-path reads.
Redirection Service
When a user clicks on a short URL, the request is routed through a load balancer to the Redirection Service, which is optimized for low-latency reads and high throughput.Client → Load Balancer → Redirection Service → Data Service → (Redis / Cassandra)https://short.ly/abc123 → short_code = abc123The Data Service first checks the Redis cache for the mapping:
GET url:abc123If the mapping is not found in Redis (cache miss), the Data Service queries Cassandra:
SELECT long_url FROM url_mapping WHERE short_code = 'abc123'SET url:abc123 "https://example.com"The Redirection Service then validates the result. If the URL exists and is not expired, it responds with an HTTP redirect:
HTTP 302 → Location: https://example.com/very/long/urlIn parallel, the Redirection Service publishes a click event to Kafka for asynchronous processing by downstream systems such as analytics, monitoring, and billing:
{
"short_code": "abc123",
"timestamp": 1714550000,
"ip": "192.168.1.1",
"user_agent": "Chrome"
}HTTP 404 → Not Found / Expired Link PageAnalytics Service
The analytics service tracks click counts and usage metrics. Instead of updating the database synchronously on every request, events are pushed to a queue (Kafka) for asynchronous processing, ensuring that the redirection path remains fast and non-blocking.Redirection Service → Kafka → Analytics ServiceThe service may store raw click events for deeper analytics:
sqlINSERT INTO url_click_events (
short_code,
event_date,
event_time,
ip,
user_agent,
referrer
) VALUES (
'abc123',
'2024-05-01',
'2024-05-01 07:53:20',
'127.0.0.1',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)',
'https://google.com'
);
Scalability, Performance, Reliability, and Security
To achieve scalability, the system must support millions of URL creations and billions of redirects without bottlenecks. This is done through horizontal scaling at every layer. Stateless services such as the URL Service and Redirection Service can be scaled behind load balancers.Write traffic is decoupled using Kafka, allowing ingestion spikes to be absorbed without overwhelming storage systems. Databases like Cassandra are chosen for their ability to scale horizontally across nodes, while Redis clusters handle high read throughput.
Partitioning strategies (e.g., based on short_code) ensure even data distribution and avoid hotspots.
For low latency, especially in the redirection path, the system follows a strict cache-first design. Most requests are served directly from Redis or even CDN edge caches, avoiding database access entirely.
We can introduce a CDN edge cache in front of the system, where every redirect request first hits the CDN. If the short_code → long_url mapping is already cached, the CDN directly returns the redirect without contacting backend services. On a cache miss, the request is forwarded to the Redirection Service, which resolves the mapping (via Redis/Cassandra) and the CDN caches the response for future requests.Only cache misses hit Cassandra, and even those results are cached immediately. All non-critical operations such as analytics and logging are handled asynchronously, ensuring that user-facing latency remains in the millisecond range.
However, serving redirects directly from the CDN introduces a tradeoff: we lose visibility into those requests. Since the backend is bypassed, we cannot reliably capture click logs, analytics, or tracking data for cache hits unless we add separate logging mechanisms (e.g., CDN logs or edge analytics).
Services are deployed across multiple availability zones and optionally across multiple regions. Load balancers distribute traffic and automatically remove unhealthy instances.
Redis uses replication and failover, while Cassandra provides data replication across nodes with tunable consistency. If a node fails, the system continues operating with minimal disruption. Clients can retry requests, and stateless services can quickly recover.
Data reliability is achieved through durable writes and idempotent processing. When a URL is created, the mapping is written to Kafka and then persisted in Cassandra. Even if retries occur, the same short_code ensures no duplicate or conflicting entries.
Strong consistency can be applied where needed (e.g., during creation), while eventual consistency is acceptable for caching layers.
The system can integrate URL validation and blacklisting services to detect malicious links at creation time. Additionally, the system may implement safe browsing checks, link preview warnings, and domain reputation scoring to protect end users.
Summary
A URL shortener like Bitly is a read-heavy, low-latency distributed system. The core ideas revolve around efficient ID generation, fast redirection using caching, scalable storage, and high availability.By focusing on optimizing the read path and ensuring reliable mappings, the system can handle massive scale while maintaining a seamless user experience.
